淄博AI大数据招聘新机遇,如何抓住热门岗位?
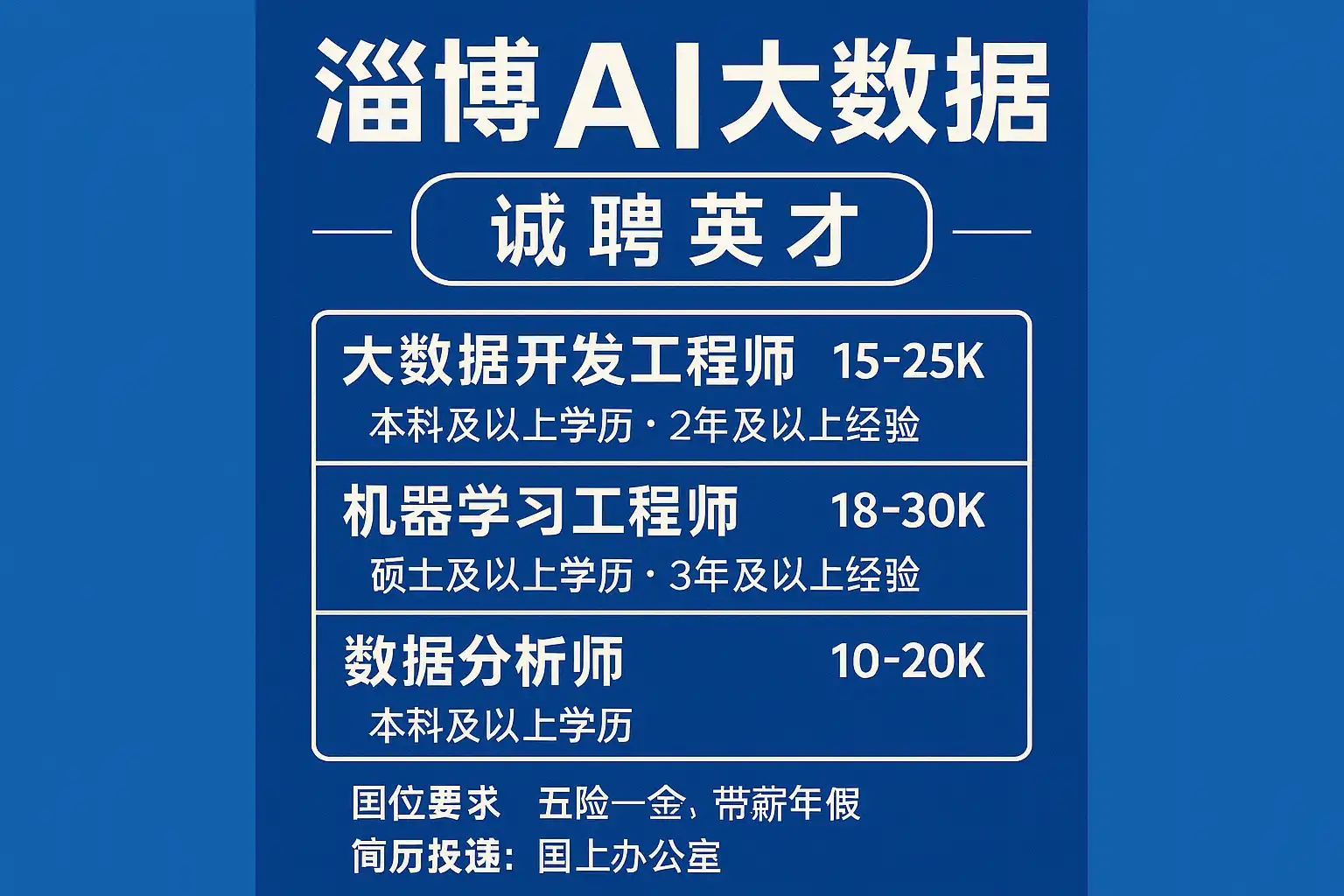
摘要:要在淄博抓住AI与大数据招聘新机遇,关键在于行动与匹配。核心做法是:1、锁定制造业、化工、新材料、医药与城市治理等本地高频场景,围绕质检、能耗优化、设备预测性维护、供应链与营销分析落地;2、构建“SQL+Python+数据建模+云与MLOps+行业知识”的复合技能矩阵,形成可交付的作品集;3、以项目产出与业务ROI说话,准备指标、数据与上线路径;4、选择园区/人社渠道、企业直招与i人事等工具,精准投递并以案例化面试拿下岗位。按此路径,你能在3个月内完成技能-项目-岗位的闭环,抓住淄博AI大数据的热门职位窗口期。
《淄博AI大数据招聘新机遇,如何抓住热门岗位?》
一、行业需求与岗位地图
- 区域场景聚焦:淄博以化工与新材料、装备制造、陶瓷与玻璃、医药与医疗器械、物流与供应链、城市治理为支柱。AI与大数据在以下环节高频出现:产线视觉质检、能耗与良率优化、预测性维护、供应链与销售预测、客户画像与营销自动化、城市治理与交通优化、政务数据治理与指标分析。
- 招聘驱动逻辑:企业更偏好能“带项目入场”的候选人,即具备数据管道建设、模型上线、可视化决策支持的端到端能力;能结合行业知识保障合规与上线效果。
- 岗位趋势:数据分析师、数据工程师、BI工程师、AI算法工程师、MLOps/平台工程师、数据产品经理、AI应用实施顾问、工业互联网解决方案工程师。
热门岗位与技能匹配表(结合淄博产业场景)
| 岗位 | 核心职责 | 关键技能 | 入门门槛 | 优先背景 | 月薪区间(淄博) |
|---|---|---|---|---|---|
| 数据分析师 | 指标体系、报表、洞察与业务建议 | SQL、Excel/Power BI、统计分析、可视化、AB测试 | 会写复杂SQL、能构建指标、能讲业务故事 | 制造/化工/医药业务分析 | 8k–15k(高级可至20k) |
| BI工程师 | 数据模型与报表开发 | 数据仓库建模(星型/雪花)、Power BI/Tableau、ETL | 能把业务转为维度模型 | IT或数据岗转型 | 10k–18k |
| 数据工程师 | 数据集成、清洗、仓库与湖的建设 | Python/Scala、Spark/Flink、Airflow、Kafka、Lakehouse | 能稳定跑起数据管道 | 大数据平台经验 | 12k–22k(高级25k+) |
| AI算法工程师 | 质检/预测/文本/推荐等模型开发 | Python、PyTorch/sklearn、CV/NLP/时序预测、特征工程 | 能在企业数据上训练与评估模型 | 竞赛/科研/制造业AI项目 | 15k–30k+ |
| MLOps工程师 | 模型部署与监控 | Docker/K8s、API、CI/CD、Prometheus/Grafana、特征存储 | 能把模型上线并稳定运行 | 平台或后端工程背景 | 18k–28k |
| 数据产品经理 | 需求分析、数据产品规划与落地 | 业务流程、指标体系、PRD、数据治理 | 能画清闭环并量化ROI | 行业解决方案/咨询背景 | 15k–25k |
| AI应用实施顾问 | 项目交付、培训与效果验收 | 需求梳理、轻开发、报表搭建、变更管理 | 能把工具落到现场 | 工业互联网实施 | 12k–20k |
| 工业互联网解决方案工程师 | 采集/边缘计算/平台集成 | OPC/Modbus、边缘网关、数据平台、可视化 | 现场经验+数据能力 | 自动化/仪控背景 | 15k–25k |
说明:
- 薪资区间随企业体量、项目复杂度与候选人实战深度浮动;技术平台经验与行业落地案例将显著抬升报价。
- “能上线”比“会算法”更值钱:简历优先展示端到端闭环与业务指标提升。
二、构建AI+数据技能矩阵
- 基础层:数据与统计
- SQL(窗口函数、复杂聚合、优化)、统计学(分布、置信区间、假设检验)、指标体系(口径统一、维度管理)。
- 工程层:数据管道与计算
- Python(Pandas、Polars)、Spark/Flink、Airflow/Kedro、Kafka、数据湖/仓(Iceberg/Hudi/Delta)、API集成。
- 模型层:AI与机器学习
- 传统ML(XGBoost、LightGBM)、时序预测(ARIMA/Prophet/LSTM)、CV(缺陷检测/分类)、NLP(RAG、信息抽取)、推荐/画像。
- 产品层:可视化与业务决策
- Power BI/Tableau、Superset、仪表盘设计、AB测试、ROI测算。
- 平台层:MLOps与云
- Docker、Kubernetes、CI/CD、模型版本管理、监控告警、推理加速。
- 合规层:数据安全与隐私
- 个人信息保护法、数据安全法、敏感数据脱敏、访问控制与审计。
90天分层学习与产出路线
| 阶段 | 目标 | 关键任务 | 可交付成果 |
|---|---|---|---|
| 0–30天 | 打基础 | SQL进阶、Python数据处理、指标口径 | 两个数据分析小项目(含报表与洞察) |
| 31–60天 | 做闭环 | Spark/Flink管道、一个ML模型(时序/CV) | 端到端项目:采集-清洗-训练-可视化 |
| 61–90天 | 上线与优化 | Docker/K8s部署、监控、AB测试 | 可复用模板与部署文档+ROI复盘 |
技能组合示例(投递对标):
- 制造业质检岗:Python+CV(缺陷检测)+数据管道+Power BI+现场流程理解。
- 能耗优化岗:时序预测+特征工程+AB测试+仪表盘+节能指标定义。
- 供应链分析岗:SQL+维度模型+预测+库存周转指标+报表故事化。
- 政务/城市治理岗:数据治理+指标体系+可视化+合规管控。
三、作品集与实战项目:如何打动招聘方
- 项目选择原则:贴近本地场景、可量化收益、可验证与可上线。
- 参考项目模板:
- 产线视觉质检:缺陷类型识别(CV+轻量模型),上线到边缘设备或API;指标:召回率/误报率/产线误停减少比例。
- 能耗与良率优化:时序预测+特征工程,设计AB测试;指标:能耗降低%、良率提升%、单位成本降低。
- 供应链与销售预测:结合历史出入库、季节性与促销活动;指标:预测MAPE、库存周转天数改善。
- 维护知识库RAG:将设备手册与维修记录索引,检索+回答提升一线效率;指标:工单处理时长下降、一次修复率提升。
- 城市治理可视化:交通拥堵热力图+事件响应仪表盘;指标:平均拥堵时长与事件响应时长下降。
- 作品集呈现结构:
- 背景与业务目标:问题定义+ROI目标。
- 数据:来源、字段字典、质量与处理。
- 方法:特征、模型与参数。
- 上线:部署架构、监控与报警。
- 结果:指标对比(前后对照),AB测试设计与统计显著性。
- 复盘:失败点、稳定性与迭代计划。
四、求职渠道与简历面试策略
-
渠道组合:
-
园区/人社:高新区、经开区企业直招;关注当地人社局公告与专场。
-
企业直投:制造、化工、新材料龙头官网与校/社招页面。
-
猎头与社群:行业微信群、GitHub/开源社区成果曝光。
-
i人事:使用智能解析与人才库检索,批量管理投递与面试安排;i人事官网地址: https://account.ihr360.com/ac/view/login/#/login/?source=aiworkseo;
-
简历结构(1页)
-
标题与标签:岗位意向+关键词(SQL/Python/Spark/PowerBI/时序/CV/MLOps)。
-
项目3则:每则含数据规模、方法、上线方式、3个量化指标(如MAPE、Recall、良率提升%、能耗下降%)。
-
技术栈:工具+平台+合规经验(脱敏、权限)。
-
教育与证书:统计/计算机/自动化相关,附竞赛或开源贡献链接。
-
面试策略
-
案例法回答:STAR结构,强调业务目标—方法—上线—指标。
-
白板题:写SQL窗口函数、解释模型评估、设计数据管道容错。
-
业务题:如何落地到产线?如何做AB测试与统计显著性?如何保障数据口径一致?
-
反问:部署环境、数据质量、上线周期、成功评价维度与团队协作方式。
五、薪酬、成长与跳槽路径
| 路径 | 起点 | 3年目标 | 关键里程碑 | 典型跃迁 |
|---|---|---|---|---|
| 数据分析师→高级/产品 | 分析与报表 | 能定义指标与推动决策 | 两个ROI项目+行业方法论 | 向数据产品经理转型 |
| BI→数据工程 | 报表与模型 | 能搭数仓与稳定管道 | ETL自动化+湖仓一体 | 平台/架构方向 |
| 算法→MLOps/解决方案 | 单点模型 | 端到端上线与监控 | 服务化部署+A/B与SLA | 技术负责人/方案架构 |
| 实施→产品/售前 | 项目交付 | 把需求转为产品能力 | 成功迭代3次+复用模板 | 方案经理/产品经理 |
薪酬提升关键:从“能做”到“能稳上线并增效”,以累计的业务指标与可复用组件作为加薪与晋升的证据。
六、企业侧需求与招聘标准拆解
| 维度 | 企业关注点 | 评估方法 | 及格线 |
|---|---|---|---|
| ROI | 提效/降本可量化 | 过往项目指标与复盘 | 指标明确且可复验 |
| 上线速度 | 交付周期与风险 | 部署方案与故障应对 | 有灰度与回滚策略 |
| 稳定性 | 监控与容错 | SLA、报警与降级 | 能应对波动与异常 |
| 合规 | 数据脱敏与权限 | 合规设计与日志审计 | 满足制度与可追溯 |
| 团队协作 | 与业务/IT配合 | 演示与沟通 | 能讲业务语言并推动 |
面试常见作业:给一份带缺失值与异常点的数据集,要求产出指标口径、清洗策略、预测模型与上线计划(含监控与AB设计)。
七、风险与避坑
- 岗位错配:只做报表却挂“算法工程师”头衔;入职前确认职责、环境与数据权限。
- 项目不可落地:数据不可用或口径混乱;先做数据审计与样本探索。
- 过度追新:大模型堆料但无场景;选择“问题驱动”,以RAG/检索或轻量模型快速验证。
- 简历堆叠:无量化指标与上线证明;项目必须给出数字与链接/截图。
- 合规忽视:采集与传输不合规;明确数据分级、脱敏与访问控制。
八、90天行动计划与资源清单
| 时间段 | 行动 | 产出 | 验证 |
|---|---|---|---|
| 0–30天 | SQL进阶+Power BI;制造能耗数据清洗与指标搭建 | 能耗仪表盘与洞察报告 | 与行业师傅复核指标 |
| 31–60天 | Spark管道+时序预测;AB测试方案 | 预测服务API+AB测试设计 | 离线对比与统计显著性 |
| 61–90天 | Docker部署+监控;质检CV项目上线 | 端到端项目与监控面板 | 历史数据回放+稳定性周报 |
资源建议:
- 文档与开源:PostgreSQL/ClickHouse、Spark/Flink、Airflow、PyTorch、LightGBM、Grafana、Superset官方文档。
- 数据集:工业能耗与设备传感器公开数据、质量检测公开集、零售交易数据。
- 方法论:AB测试、指标治理、数据质量管理、灰度与回滚策略。
总结与行动步骤:
- 总结:在淄博,AI与大数据岗位的核心是“行业场景驱动+端到端交付”。从数据到模型再到部署与ROI验证,形成闭环,你的竞争力会显著提升。
- 立即行动:
- 选定一个本地高频场景(如能耗或质检),明确业务指标与收益目标。
- 完成90天路线中的第一个端到端项目,并输出可视化与部署文档。
- 在简历中以量化指标与上线截图展示成果,准备STAR式面试答案。
- 通过园区直招与i人事等渠道批量投递、跟进面试进度;使用项目ROI作为谈薪筹码。
- 入职后以AB测试与监控固化价值,持续沉淀可复用模板,形成职场护城河。
精品问答:
淄博AI大数据招聘新机遇有哪些热门岗位?
最近听说淄博的AI大数据行业招聘很火爆,我想了解具体有哪些热门岗位?这些岗位的职责和要求是什么?
淄博AI大数据招聘新机遇主要集中在以下热门岗位:
- 数据科学家:负责数据分析与模型构建,要求掌握Python、机器学习等技术。
- 大数据工程师:负责数据平台搭建与维护,熟悉Hadoop、Spark等大数据技术栈。
- AI算法工程师:专注于深度学习和算法优化,需具备TensorFlow、PyTorch经验。
- 数据分析师:通过数据报告支持业务决策,要求熟悉SQL和数据可视化工具。
根据2023年淄博地区招聘数据显示,数据科学家和大数据工程师的需求量增长超过35%,是最具发展潜力的岗位。
如何提升自己在淄博AI大数据领域的竞争力?
我想进入淄博的AI大数据领域,但感觉自己技术还不够强,应该如何提升竞争力,才能抓住招聘新机遇?
提升淄博AI大数据领域竞争力可以从以下几个方面入手:
| 提升方向 | 具体措施 | 作用说明 |
|---|---|---|
| 技术技能 | 学习Python、R语言,熟练掌握机器学习和深度学习算法 | 满足岗位的核心技术需求,提升项目实战能力 |
| 项目经验 | 参与开源项目或企业实习,积累大数据处理案例 | 通过实际案例展示能力,增强简历竞争力 |
| 证书认证 | 获取相关认证如数据分析师证书、Hadoop认证 | 证明专业水平,增加招聘方认可度 |
| 软技能 | 提升沟通和团队协作能力 | 促进跨部门合作,提高工作效率 |
根据行业报告,拥有丰富项目经验的求职者获得面试机会的概率提高了40%。
淄博AI大数据岗位的薪资水平如何?
我想知道淄博AI大数据相关岗位的薪资大概是多少?这对我决定是否换工作很重要,希望了解具体数据。
根据2023年淄博地区AI大数据岗位薪资调研,薪资水平如下:
| 岗位 | 平均月薪(元) | 薪资区间(元) | 备注 |
|---|---|---|---|
| 数据科学家 | 18,000 | 12,000 - 25,000 | 经验丰富者可达30,000以上 |
| 大数据工程师 | 16,500 | 11,000 - 23,000 | 技术栈广泛者薪资更高 |
| AI算法工程师 | 17,500 | 13,000 - 24,000 | 掌握前沿算法者更受欢迎 |
| 数据分析师 | 12,000 | 8,000 - 16,000 | 入门门槛相对较低 |
整体来看,淄博AI大数据岗位的薪资水平较去年增长约15%,显示市场需求旺盛。
淄博AI大数据招聘市场未来发展趋势如何?
我对淄博AI大数据招聘市场的未来很感兴趣,想知道未来几年这个行业的招聘趋势和发展机遇有哪些?
淄博AI大数据招聘市场未来呈现以下发展趋势:
- 需求持续增长:预计2024-2026年,淄博AI大数据相关岗位需求年均增长率将达到20%以上。
- 技术融合趋势:AI、大数据与物联网、云计算等技术深度融合,岗位技能要求更加多元化。
- 智能制造推动:淄博作为重要制造业基地,智能制造升级推动大数据和AI岗位需求增加。
- 政府支持加码:政策扶持和人才引进计划带动行业快速发展。
案例:某淄博智能制造企业2023年招聘数据科学家职位,招聘人数同比增长50%,体现了行业对人才的旺盛需求。
文章版权归"
转载请注明出处:https://irenshi.cn/p/400257/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。